Tips Membuat Animasi Scroll Selalu Berjalan
Daftar Isi
PendahuluanContoh HasilHTML DasarCSSBodyContainer SliderContent SlidernyaGanti ImagePenutup
Pendahuluan
Slider yang bergerak secara terus-menerus menjadi elemen kunci dalam menciptakan pengalaman pengguna yang dinamis dan menyenangkan, dengan arus visual yang tak terputus, perhatian pengunjung akan tertahan lebih lama, meningkatkan interaksi dan kepuasan karena pada slider mengandung banyak informasi yang sampai kepada user lewat pergerakannya. Menggunakan Tailwind CSS, pembuatan slider otomatis ini dapat dilakukan dengan langkah-langkah sederhana yang memanfaatkan utilitas kelas yang terstruktur untuk mengatur animasi dan responsivitas secara efisien. Teknik slicing yang tepat pada desain modern tidak hanya memudahkan implementasi, tetapi juga menghasilkan tampilan yang memukau, menjadikan setiap pergeseran slide sebuah sajian visual yang menarik dan estetis.
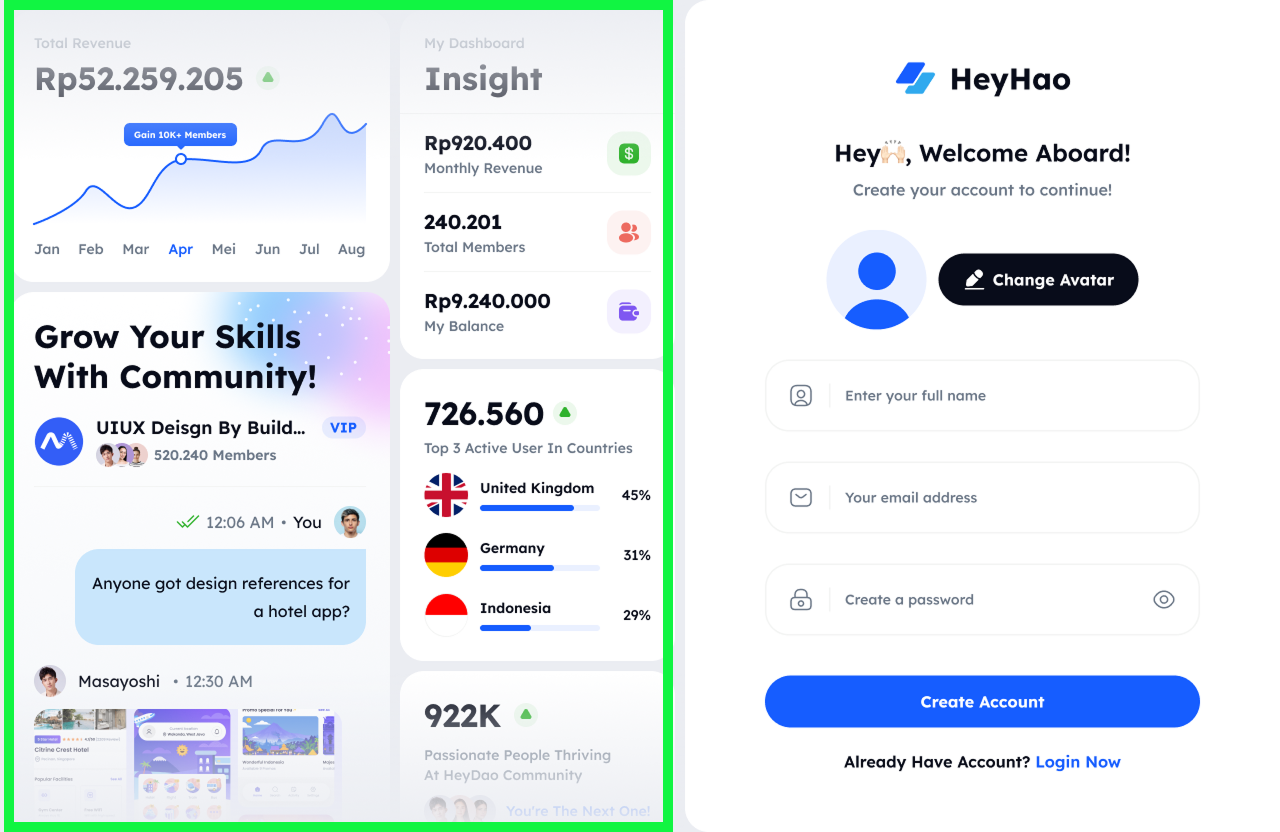
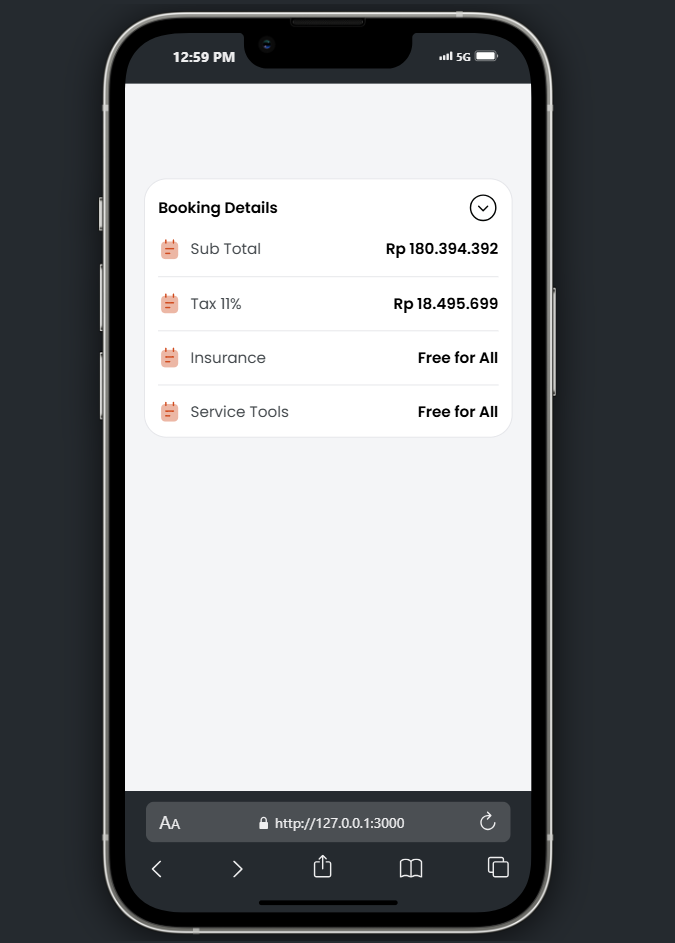
Contoh Hasil
HTML Dasar
Buat folder lalu buat index.html di dalamnya dan letakkan kode berikut ke dalam file tersebut :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>HeyHao - Slider</title>
<script src="<https://cdn.jsdelivr.net/npm/@tailwindcss/browser@4>"></script>
</head>
<body></body>
</html>
Maka penjelasannya :
<!DOCTYPE html>
Mendeklarasikan dokumen sebagai HTML5, memastikan browser merender halaman dalam “standards mode” modern, bukan “quirks mode” lama yang berusaha kompatibel dengan HTML versi terdahulu.
<html lang="en">
Menjadi elemen akar dari seluruh dokumen HTML, dengan atribut lang="en" untuk menandakan bahasa utama adalah Inggris berguna bagi mesin pencari (SEO), pembaca layar, dan sistem lokalisasi.
<head> … </head>
Bagian metadata dan instruksi untuk browser; tidak menampilkan konten langsung. Berisi pengaturan karakter, responsivitas, judul, dan pemanggilan library.
<meta charset="UTF-8" />
Menetapkan set karakter UTF-8, mendukung hampir semua aksara dunia (termasuk non-Latin dan emoji) dan mencegah masalah tampilan karakter rusak.
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
Mengatur viewport agar lebarnya sama dengan lebar layar perangkat dan skala awal 100%, sehingga desain responsif bekerja dengan baik di ponsel dan tablet.
<title>HeyHao - Slider</title>
Menentukan judul halaman yang tampil di tab browser dan sebagai judul di hasil pencarian sebaiknya singkat, deskriptif, dan mencantumkan kata kunci utama.
<script src="<https://cdn.jsdelivr.net/npm/@tailwindcss/browser@4>"></script>
Mengimpor Tailwind CSS via CDN dalam mode “browser” untuk kompilasi utilitas on-the-fly, memudahkan prototyping tanpa setup build tool; namun kurang ideal untuk produksi karena performa dan kontrol tree-shaking.
<body></body>
Wadah konten utama yang akan dirender (teks, gambar, slider, dan elemen interaktif lainnya). Saat ini kosong Anda dapat menambahkan struktur slider dengan utilitas Tailwind dan logika JavaScript agar berjalan otomatis.
CSS
Lalu lanjut pada CSS nya untuk menentukan pergerakan animas dan durasinya seperti berikut :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>HeyHao - Slider</title>
<script src="<https://cdn.jsdelivr.net/npm/@tailwindcss/browser@4>"></script>
<!-- dari sini -->
<style>
.slide-top {
animation: slide-top 20s infinite linear;
}
.slide-bottom {
animation: slide-bottom 20s infinite linear;
}
@keyframes slide-top {
0% {
transform: translateY(0);
}
100% {
transform: translateY(-100%);
}
}
@keyframes slide-bottom {
0% {
transform: translateY(-100%);
}
100% {
transform: translateY(0);
}
}
</style>
<!-- sampai sini -->
</head>
<body></body>
</html>
Maka penjelasannya :
<!-- dari sini --> hingga <!-- sampai sini -->
Komentar HTML yang menandai awal dan akhir blok kustom CSS, memudahkan pengembang untuk mengenali area styling khusus pada kode.
<style> … </style>
Tag HTML untuk menuliskan CSS langsung di dalam dokumen, digunakan di sini untuk mendefinisikan animasi slider tanpa membuat file CSS eksternal.
.slide-top { animation: slide-top 20s infinite linear; }
Kelas CSS yang menerapkan animasi slide-top selama 20 detik, berjalan terus-menerus (infinite) dengan kecepatan konstan (linear), memindahkan elemen dari posisi awal ke atas.
.slide-bottom { animation: slide-bottom 20s infinite linear; }
Kelas CSS yang menerapkan animasi slide-bottom dengan durasi dan perilaku sama, namun memindahkan elemen dari atas ke posisi akhir asalnya.
@keyframes slide-top { … }
Mendefinisikan rangkaian frame animasi dengan nama slide-top:
0% { transform: translateY(0); }: elemen berada pada posisi vertikal awal.100% { transform: translateY(-100%); }: elemen digeser ke atas sebesar 100% tinggi elemen itu sendiri.
@keyframes slide-bottom { … }
Mendefinisikan rangkaian frame animasi dengan nama slide-bottom:
0% { transform: translateY(-100%); }: elemen dimulai dari posisi terangkat penuh ke atas (di luar layar atas).100% { transform: translateY(0); }: elemen kembali ke posisi vertikal awalnya.
Dengan setup ini, elemen yang diberi kelas slide-top akan terus bergerak naik, sedangkan elemen dengan kelas slide-bottom bergerak turun, menciptakan efek slider yang saling berkelanjutan.
Body
Lalu sekarang lanjut ke area tag body, pada area ini kita harus membuat Container Slider dulu, maka :
Container Slider
perhatikan yang mengandung
<!-- dari sini --> <!-- sampai sini -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>HeyHao - Slider</title>
<script src="<https://cdn.jsdelivr.net/npm/@tailwindcss/browser@4>"></script>
<style>
.slide-top {
animation: slide-top 20s infinite linear;
}
.slide-bottom {
animation: slide-bottom 20s infinite linear;
}
@keyframes slide-top {
0% {
transform: translateY(0);
}
100% {
transform: translateY(-100%);
}
}
@keyframes slide-bottom {
0% {
transform: translateY(-100%);
}
100% {
transform: translateY(0);
}
}
</style>
</head>
<body>
<!-- dari sini -->
<div class="flex min-h-screen bg-[#EBEDF2]">
<section id="ContainerBackgroundImages" class="flex w-full max-w-[685px]">
<span class="fixed w-[685px] top-0 left-0 right-0 h-[160px] bg-[linear-gradient(0deg,rgba(235,237,242,0)_0%,#EBEDF2_100%)] z-10"></span>
<span class="fixed w-[685px] bottom-0 left-0 right-0 h-[160px] bg-[linear-gradient(0deg,#EBEDF2_0%,rgba(235,237,242,0)_100%)] z-10"></span>
<section id="BackgroundImages" class="fixed top-0 h-screen w-full max-w-[685px] overflow-hidden">
<div class="flex justify-center gap-[10px]">
<!-- konten slidernya -->
</div>
</section>
</section>
<!-- Container Inputs -->
</div>
<!-- sampai sini -->
</body>
</html>
Maka Penjelasan :
<div class="flex min-h-screen bg-[#EBEDF2]">
Membuat kontainer utama dengan display flex, tinggi minimum setara viewport penuh (min-h-screen), dan background warna abu-abu muda #EBEDF2, sehingga seluruh area layar menjadi fleksibel dan memiliki latar yang konsisten.
<section id="ContainerBackgroundImages" class="flex w-full max-w-[685px]">
Bagian wrapper untuk gambar latar slider, bersifat fleksibel (flex), memenuhi lebar penuh parent (w-full), namun dibatasi maksimal lebar 685px (max-w-[685px]) agar slider tidak melebar di layar yang sangat lebar.
<span class="fixed w-[685px] top-0 left-0 right-0 h-[160px] bg-[linear-gradient(0deg,rgba(235,237,242,0)_0%,#EBEDF2_100%)] z-10"></span>
Elemen overlay gradient atas:
fixed: selalu di posisi view port.w-[685px], h-[160px]: ukuran tepat 685×160px.top-0 left-0 right-0: melekat di sisi atas.bg-[linear-gradient(...)]: menambahkan fade dari transparan ke warna latar.z-10: menempatkan overlay di atas layer konten gambar.<span class="fixed w-[685px] bottom-0 left-0 right-0 h-[160px] bg-[linear-gradient(0deg,#EBEDF2_0%,rgba(235,237,242,0)_100%)] z-10"></span>
Elemen overlay gradient bawah:
Serupa dengan overlay atas, tetapi bottom-0 untuk melekat di bawah.Gradien terbalik, membuat efek fade di bagian bawah kontainer.<section id="BackgroundImages" class="fixed top-0 h-screen w-full max-w-[685px] overflow-hidden">
Kontainer gambar latar yang diposisikan fixed memenuhi seluruh tinggi layar (h-screen) dan lebar hingga 685px, dengan overflow-hidden untuk menyembunyikan bagian gambar yang keluar area, menciptakan efek slider yang bersih.
<div class="flex justify-center gap-[10px]">
Wadah bagi elemen slide:
flex untuk layout horizontal.justify-center meratakan konten di tengah.gap-[10px] memberi jarak 10px antar slide.<!-- konten slidernya -->
Komentar penanda di mana markup elemen slide (misalnya <img> atau <div>) akan diletakkan untuk membentuk slider.
<!-- Container Inputs -->
Komentar penanda bagi kontainer input biasanya tempat form atau kontrol navigasi slider diletakkan di samping konten gambar.
Content Slidernya
Perhatikan pada :
<!-- slider 1 --> dan <!-- akhir slider 2 -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>HeyHao - Slider</title>
<script src="<https://cdn.jsdelivr.net/npm/@tailwindcss/browser@4>"></script>
<style>
.slide-top {
animation: slide-top 20s infinite linear;
}
.slide-bottom {
animation: slide-bottom 20s infinite linear;
}
@keyframes slide-top {
0% {
transform: translateY(0);
}
100% {
transform: translateY(-100%);
}
}
@keyframes slide-bottom {
0% {
transform: translateY(-100%);
}
100% {
transform: translateY(0);
}
}
</style>
</head>
<body>
<div class="flex min-h-screen bg-[#EBEDF2]">
<section id="ContainerBackgroundImages" class="flex w-full max-w-[685px]">
<span class="fixed w-[685px] top-0 left-0 right-0 h-[160px] bg-[linear-gradient(0deg,rgba(235,237,242,0)_0%,#EBEDF2_100%)] z-10"></span>
<span class="fixed w-[685px] bottom-0 left-0 right-0 h-[160px] bg-[linear-gradient(0deg,#EBEDF2_0%,rgba(235,237,242,0)_100%)] z-10"></span>
<section id="BackgroundImages" class="fixed top-0 h-screen w-full max-w-[685px] overflow-hidden">
<div class="flex justify-center gap-[10px]">
<!-- dari sini -->
<!-- slider 1 -->
<div class="flex flex-col w-[380px] gap-[10px]">
<div class="slider w-[380px]">
<div class="slide-top flex flex-col gap-[10px]">
<img src="assets/images/thumbnails/auth-1.png" alt="image" />
<img src="assets/images/thumbnails/auth-2.png" alt="image" />
<img src="assets/images/thumbnails/auth-3.png" alt="image" />
<img src="assets/images/thumbnails/auth-1.png" alt="image" />
<img src="assets/images/thumbnails/auth-2.png" alt="image" />
<img src="assets/images/thumbnails/auth-3.png" alt="image" />
</div>
</div>
<div class="slider w-[380px]">
<div class="slide-top flex flex-col gap-[10px]">
<img src="assets/images/thumbnails/auth-1.png" alt="image" />
<img src="assets/images/thumbnails/auth-2.png" alt="image" />
<img src="assets/images/thumbnails/auth-3.png" alt="image" />
<img src="assets/images/thumbnails/auth-1.png" alt="image" />
<img src="assets/images/thumbnails/auth-2.png" alt="image" />
<img src="assets/images/thumbnails/auth-3.png" alt="image" />
</div>
</div>
</div>
<!-- akhir slider 1 -->
<!-- slider 2 -->
<div class="flex flex-col w-[275px] gap-[10px]">
<div class="slider w-[275px]">
<div class="slide-bottom flex flex-col gap-[10px]">
<img src="assets/images/thumbnails/auth-4.png" alt="image" />
<img src="assets/images/thumbnails/auth-5.png" alt="image" />
<img src="assets/images/thumbnails/auth-6.png" alt="image" />
<img src="assets/images/thumbnails/auth-4.png" alt="image" />
<img src="assets/images/thumbnails/auth-5.png" alt="image" />
<img src="assets/images/thumbnails/auth-6.png" alt="image" />
</div>
</div>
<div class="slider w-[275px]">
<div class="slide-bottom flex flex-col gap-[10px]">
<img src="assets/images/thumbnails/auth-4.png" alt="image" />
<img src="assets/images/thumbnails/auth-5.png" alt="image" />
<img src="assets/images/thumbnails/auth-6.png" alt="image" />
<img src="assets/images/thumbnails/auth-4.png" alt="image" />
<img src="assets/images/thumbnails/auth-5.png" alt="image" />
<img src="assets/images/thumbnails/auth-6.png" alt="image" />
</div>
</div>
</div>
<!-- akhir slider 2 -->
<!-- sampai sini -->
</div>
</section>
</section>
<!-- Container Inputs -->
</div>
</body>
</html>
Penjelasan :
<!-- slider 1 -->
Slider ini terdiri dari dua blok vertikal identik yang masing-masing berukuran 380px (“slider w-[380px]”) dan disusun ulang secara vertikal (flex flex-col gap-[10px]), dengan jarak 10px antar elemen.
.slider (wrapper)
Menjadi kontainer berukuran tepat 380px yang menahan elemen slide, dan berfungsi sebagai “viewport” tempat animasi slide-top terjadi.
.slide-top flex flex-col gap-[10px]
Mengaplikasikan animasi slide-top (bergerak ke atas selama 20 detik secara linear dan terus-menerus) pada daftar gambar yang disusun secara kolom dengan jarak 10px.
Duplikasi gambar: Setiap thumbnail muncul dua kali berurutan (auth-1, auth-2, auth-3, kemudian ulang) untuk memastikan ketika animasi mendorong daftar ke atas, alur loop-nya mulus tanpa jeda.<img src="…auth-1.png" alt="image" /> dkk.
Thumbnail gambar slide yang akan berpindah bergantian. Atribut alt sederhana “image” bisa ditingkatkan dengan deskripsi yang lebih spesifik untuk aksesibilitas.
<!-- slider 2 -->
Mirip dengan slider pertama, namun lebih sempit (275px) dan animasinya terbalik (slide-bottom).
Kontainer Utama
div.flex.flex-col.w-[275px].gap-[10px] menata dua slider di dalam kolom selebar 275px, dengan gap 10px.
.slider w-[275px]
Viewport untuk setiap animasi, membatasi lebar slide agar tidak melebihi 275px.
.slide-bottom flex flex-col gap-[10px]
Menerapkan animasi slide-bottom (dimulai dari -100% ke posisi semula dalam 20 detik, linear, infinite) pada set gambar. Duplikasi thumbnail (auth-4, auth-5, auth-6) memastikan loop visual tanpa jeda.
Thumbnail Gambar
Gambar auth-4.png hingga auth-6.png diulang dua kali agar saat animasi kembali ke awal, transisinya halus dan tidak ada “lompat” pada pergantian.
Dengan struktur ini, kedua slider menampilkan deretan gambar yang bergerak terus-menerus slider pertama naik (slide-top) dan slider kedua turun (slide-bottom) menciptakan kontras visual dinamis pada tampilan modern Kalian. Di dalam setiap blok “slider 1 atau 2” kamu akan melihat dua buah elemen <div class="slider w-[...px]"> yang struktur dan isinya identik. Alasan utamanya ada dua adalah untuk menciptakan efek looping yang mulus tanpa jeda
Ganti Image
Setelah itu tinggal kalian ubah gambar sesuai dengan yang kalian inginkan.
Penutup
dengan mengintegrasikan slider otomatis yang halus dan menarik melalui Tailwind CSS, kalian tidak hanya menghadirkan tampilan modern yang memukau, tetapi juga mengukuhkan kesan profesional dan interaktif yang akan membuat pengguna selalu ingin kembali ke halaman kalian.
Bila ingin mempelajari secara detail kalian berada di tempat yang tepat, akses kelas BuildWithAngga dan rasanya kekayaan ilmu yang akan kalian dapatkan.
Terimakasih!

 Akses kelas selamanya
Akses kelas selamanya



 Masuk /
Daftar
Masuk /
Daftar